Comment l’IA transcrit un fichier audio : reconnaissance vocale, diarisation et le casse-tête de l’empreinte vocale en Europe
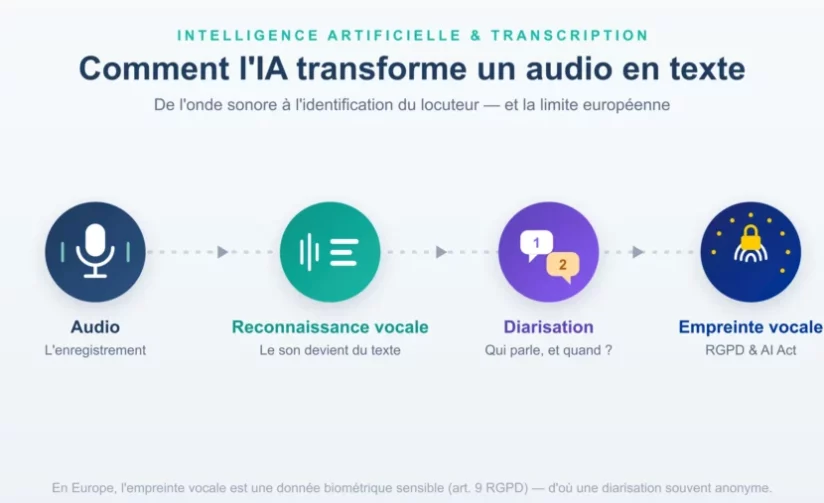
La transcription automatique permet aujourd’hui de transformer une réunion en texte exploitable en quelques minutes seulement. Derrière cette simplicité apparente se cache pourtant une chaîne technologique complexe : reconnaissance vocale (ASR), séparation des interlocuteurs (diarisation) et, parfois, identification des voix.
Comprendre ces étapes est essentiel, car elles ne soulèvent pas les mêmes enjeux techniques ni les mêmes contraintes juridiques, notamment en Europe où le traitement de la voix peut rapidement entrer dans le champ des données biométriques sensibles.
✔ La transcription (ASR) : transformer la parole en texte structuré grâce à l’IA
✔ La diarisation : distinguer automatiquement les différents intervenants sans connaître leur identité
✔ La limite critique : l’identification d’une personne d’un fichier à l’autre via son empreinte vocale
✔ Le cadre légal : RGPD et AI Act encadrent strictement les usages biométriques en entreprise
✔ Le bon usage : privilégier la diarisation anonyme pour rester conforme et efficace
Transformer une réunion d’une heure en texte propre, attribué à chaque participant, en quelques minutes : c’est aujourd’hui banal. Derrière cette magie apparente se cache une chaîne technologique précise. Et un sujet que beaucoup d’éditeurs de logiciels passent sous silence : en Europe, reconnaître automatiquement « qui parle » d’un enregistrement à l’autre touche à une donnée parmi les plus protégées qui soient.
Voici, étape par étape, comment l’IA retranscrit — et où la loi pose ses limites.
La reconnaissance automatique de la parole (en anglais Automatic Speech Recognition, ou ASR) est le cœur du système. Son rôle : convertir une onde sonore en mots écrits. Elle procède en plusieurs temps.
Les modèles récents fusionnent ces étapes dans une seule architecture dite « de bout en bout » (les modèles de type transformeur, comme ceux de la famille Whisper). Entraînés sur d’immenses corpus audio + texte multilingues, ils transcrivent directement, gèrent les accents, la ponctuation et même la traduction. C’est ce saut de qualité qui a rendu la transcription automatique réellement utilisable en entreprise depuis quelques années.
Une transcription brute donne un mur de texte. Pour qu’elle soit utile — un compte rendu de réunion, un verbatim d’entretien — il faut séparer les intervenants. C’est le rôle de la diarisation (de l’anglais diarization), qui répond à la question « qui parle, et quand ? ».
Le processus se déroule ainsi :
Point essentiel et souvent mal compris : à ce stade, l’IA ne connaît pas l’identité réelle des personnes. Elle constate seulement que la voix A est différente de la voix B à l’intérieur du même fichier. C’est un regroupement relatif, anonyme, valable le temps d’un enregistrement.
C’est ici que tout change. Imaginez vouloir que le logiciel reconnaisse automatiquement votre directrice commerciale dans toutes vos réunions, sans avoir à la ré-étiqueter à chaque fois. Pour cela, il faut conserver une référence de sa voix : un vecteur de signature stocké durablement, auquel comparer toute nouvelle voix entendue.
Cette référence persistante, c’est ce qu’on appelle une empreinte vocale. Et techniquement, c’est exactement la même logique que l’empreinte digitale : un gabarit unique qui permet d’identifier une personne précise, où qu’elle se trouve.
C’est précisément ce passage — du regroupement anonyme à l’identification nominative et persistante — qui fait basculer le traitement dans une catégorie juridique à part en Europe.
Le RGPD distingue les données personnelles ordinaires des « catégories particulières », dites données sensibles. L’article 9 du RGPD interdit, par principe, le traitement des données biométriques dès lors qu’elles servent à identifier une personne de manière unique — au même titre que les empreintes digitales ou la reconnaissance de l’iris. La voix en fait explicitement partie.
La distinction est subtile mais décisive :
Autrement dit : transcrire et diariser un audio (étapes 1 et 2) ne pose pas, en soi, ce problème. C’est l’étape 3 — créer et stocker un gabarit d’identification — qui fait entrer dans le régime le plus strict du droit européen.
L’interdiction de l’article 9 connaît des exceptions, mais elles sont restrictives. Dans le monde de l’entreprise, la plus courante est le consentement explicite de la personne. Or ce consentement doit être libre, spécifique, éclairé et révocable à tout moment.
C’est là que le bât blesse. Les autorités de protection des données considèrent qu’il existe un déséquilibre entre un employeur et ses salariés : un employé peut difficilement refuser « librement » que sa voix soit enregistrée comme gabarit biométrique. Le consentement y est donc jugé fragile, voire invalide. Et dès qu’une personne retire son consentement, tout traitement fondé sur cette base doit cesser et l’empreinte être supprimée — ce qui rend ces systèmes lourds à exploiter dans la durée.
Au RGPD se superpose désormais le règlement européen sur l’intelligence artificielle (AI Act, entré en vigueur le 1ᵉʳ août 2024 et applicable par étapes). Il classe les systèmes biométriques parmi les usages à haut risque, et interdit purement et simplement certaines pratiques — comme la reconnaissance des émotions sur le lieu de travail ou la catégorisation biométrique révélant des données sensibles, prohibées depuis février 2025.
Les obligations applicables aux systèmes d’identification biométrique à haut risque, elles, ont vu leur calendrier remanié : initialement prévues pour le 2 août 2026, elles s’appliqueront finalement à compter du 2 décembre 2027, à la suite de l’accord politique sur le « Digital Omnibus » conclu en mai 2026.
Le tout sous la menace de sanctions très dissuasives : jusqu’à 20 M€ ou 4 % du chiffre d’affaires mondial pour le RGPD, et jusqu’à 35 M€ ou 7 % pour les manquements les plus graves à l’AI Act.
Pour une entreprise, le message est clair :
C’est la raison pour laquelle la plupart des outils de transcription disponibles en Europe, comme notre solution Kairos, s’arrêtent volontairement à la diarisation anonyme : c’est techniquement suffisant pour 90 % des besoins, et cela évite d’entrer dans une zone juridique à très haut risque.
La transcription par IA repose sur trois briques : la reconnaissance vocale (du son vers le texte), la diarisation (séparer les voix au sein d’un fichier) et, pour aller plus loin, l’empreinte vocale (identifier une personne d’un fichier à l’autre). Les deux premières sont aujourd’hui matures et largement utilisables. La troisième, en revanche, fait basculer le traitement dans le régime des données biométriques sensibles, étroitement encadré en Europe par le RGPD et l’AI Act. Comprendre cette frontière, c’est comprendre pourquoi votre logiciel de réunion vous propose « Locuteur 1 » ou « speacker 1 »plutôt que votre nom.
ASR, diarisation et conformité RGPD : Kairos Meet+ automatise vos comptes rendus tout en respectant les contraintes européennes sur les données biométriques. Une solution conçue pour transformer vos réunions en documents structurés, sans identification sensible des intervenants.
La reconnaissance vocale transcrit ce qui est dit (le contenu). La diarisation détermine qui le dit (l’attribution des passages à chaque intervenant). Les deux fonctionnent ensemble mais répondent à des questions différentes.

Non. Elle distingue les voix les unes des autres au sein d’un même enregistrement et les nomme « Locuteur 1 », « Locuteur 2 ». Elle ne sait pas qui sont réellement ces personnes.
C’est davantage : c’est une donnée biométrique sensible au sens de l’article 9 du RGPD, dès lors qu’elle sert à identifier quelqu’un de façon unique. Son traitement est interdit par principe, sauf exception comme le consentement explicite.
Oui, à condition de respecter le cadre : information des participants, base légale adaptée, et une très grande prudence particulière si l’on conserve des empreintes vocales identifiantes. La diarisation anonyme, elle, est l’usage standard et le moins risqué.

Des questions ? Besoin d’un devis ?